고정 헤더 영역
상세 컨텐츠
본문
1. 손글씨 인식 모델 만들기


`device = 'cuda' if torch.cuda.is_available() else 'cpu'` 코드는
PyTorch에서 GPU를 사용할 수 있는지 확인하고, GPU가 사용 가능하면 `device`
변수를 'cuda'로 설정하고, 그렇지 않으면 'cpu'로 설정하는 역할을 합니다.
설명을 자세히 하면 다음과 같습니다:
1. `torch.cuda.is_available()` 함수는 현재 시스템에서 CUDA를 지원하는지
확인합니다. CUDA는 NVIDIA의 GPU를 사용하여 연산을 가속화하는 기술입니다. 이
함수는 GPU가 사용 가능한 경우 `True`를 반환하고, 그렇지 않은 경우 `False`를
반환합니다.
2. `device = 'cuda' if torch.cuda.is_available() else 'cpu'` 구문은
조건문을 사용하여 GPU의 가용성을 확인하고, 그 결과에 따라 `device` 변수에
값을 할당합니다. `torch.cuda.is_available()` 함수의 결과가 `True`이면,
`device` 변수는 'cuda'로 설정되며 GPU를 사용합니다. 만약 `torch.cuda.
is_available()` 함수의 결과가 `False`이면, `device` 변수는 'cpu'로 설정되며
CPU를 사용합니다.
3. `print(device)` 구문은 `device` 변수의 값을 출력합니다. 이를 통해 현재
사용 가능한 디바이스가 GPU인지 CPU인지를 확인할 수 있습니다. 출력 결과로
'cuda'가 나오면 GPU를 사용할 수 있고, 'cpu'가 나오면 GPU를 사용할 수 없는
것입니다.
이러한 구문을 사용하여 CUDA를 지원하는 경우 GPU를 사용하고, 그렇지 않은
경우 CPU를 사용하여 PyTorch 모델 및 데이터를 처리할 수 있습니다.

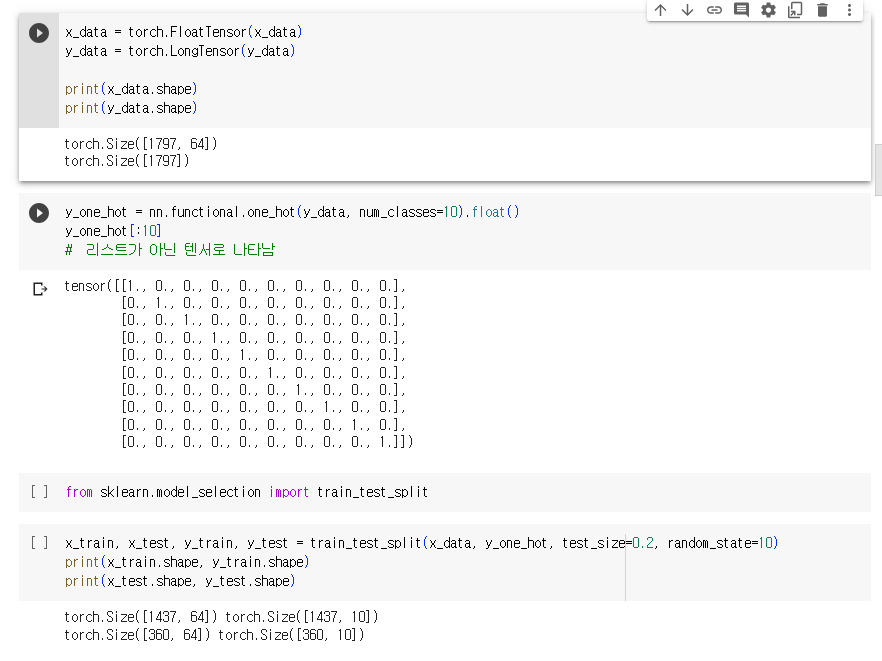
위의 코드에서 출력된 결과는 다음과 같습니다:
1. `(1797, 64)`는 `x_data`의 형태를 나타냅니다. 이는 데이터셋에 총 1797개의
이미지가 있으며, 각 이미지는 64개의 특징(또는 픽셀)로 구성되어 있다는 것을
의미합니다. 즉, 각 이미지는 8x8 픽셀의 2차원 배열로 표현되고, 이를 1차원
벡터로 펼친 형태입니다.
2. `(1797,)`는 `y_data`의 형태를 나타냅니다. 이는 데이터셋에 대한 정답
레이블의 형태입니다. 정답 레이블은 각 이미지에 해당하는 숫자를 나타내며,
데이터셋에는 총 1797개의 이미지에 대한 정답 레이블이 있다는 것을
의미합니다. 형태가 `(1797,)`인 것은 1차원 배열 형태임을 나타냅니다.
따라서, `x_data`는 1797개의 이미지에 대한 특징 벡터 데이터이며, `y_data`는
해당 이미지에 대한 정답 레이블을 나타냅니다.


위의 코드는 Matplotlib를 사용하여 데이터셋에서 일부 이미지를 시각화하는
역할을 합니다.
설명을 자세히 하면 다음과 같습니다:
1. `fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(14, 8))` 코드는 2x5
크기의 서브플롯 그리드를 생성합니다. `fig` 변수에는 전체 그림을 나타내는
Figure 객체가 저장되고, `axes` 변수에는 각각의 서브플롯에 대한 Axes 객체가
저장됩니다. `figsize=(14, 8)`는 그림의 전체 크기를 설정하는 매개변수입니다.
2. `for i, ax in enumerate(axes.flatten()):` 코드는 `axes` 변수에서 각각의
서브플롯에 대해 반복합니다. `flatten()` 함수는 2차원 배열을 1차원으로
펼치는 역할을 합니다. `i`는 반복 인덱스를 나타내고, `ax`는 해당 서브플롯에
대한 Axes 객체를 나타냅니다.
3. `ax.imshow(x_data[i].reshape((8, 8)), cmap='gray')` 코드는 `x_data`에서
가져온 이미지를 8x8 크기로 변형하여 `ax` 서브플롯에 이미지로 표시합니다.
`cmap='gray'`는 이미지를 흑백으로 표시하기 위해 사용되는 컬러맵을
지정합니다.
4. `ax.set_title(y_data[i])` 코드는 `ax` 서브플롯에 해당하는 이미지의 정답
레이블을 제목으로 설정합니다. `y_data[i]`는 해당 이미지에 대한 정답
레이블을 가져옵니다.
5. `ax.axis('off')` 코드는 `ax` 서브플롯의 축을 제거합니다. 이로써 이미지
주위에 축과 눈금을 표시하지 않습니다.
결과적으로, 위의 코드는 `x_data`에 있는 일부 이미지를 2x5 형태의 서브플롯
그리드에 표시하고, 각 이미지에 대한 정답 레이블을 제목으로 표시합니다. 각
서브플롯은 8x8 크기의 이미지로 표시되며, 축과 눈금은 제거됩니다. 이를 통해
데이터셋의 일부 이미지를 시각적으로 확인할 수 있습니다.
2. 데이터 로더
- 데이터의 양이 많을 때, 배치 단위로 학습하는 방법

loader = torch.utils.data.DataLoader(
dataset=list(zip(x_train, y_train)),
batch_size=64,
shuffle=True
)
imgs, labels = next(iter(loader))
fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(14, 14))
for ax, img, label in zip(axes.flatten(), imgs, labels):
ax.imshow(img.reshape((8, 8)), cmap='gray')
ax.set_title(str(torch.argmax(label)))
ax.axis('off')
위의 코드는 PyTorch의 `DataLoader`를 사용하여 데이터셋의 이미지를 배치
단위로 로드하고 시각화하는 역할을 합니다.
설명을 자세히 하면 다음과 같습니다:
1. `loader = torch.utils.data.DataLoader(dataset=list(zip(x_train,
y_train)), batch_size=64, shuffle=True)` 코드는 데이터셋인 `x_train`과
`y_train`을 묶어서 튜플 형태로 만든 후, 이를 리스트로 변환합니다. 그리고
`torch.utils.data.DataLoader`를 사용하여 데이터 로더 `loader`를 생성합니다.
`batch_size=64`는 각 배치에 포함될 이미지와 레이블의 개수를 나타냅니다.
`shuffle=True`는 데이터를 섞을지 여부를 나타냅니다.
2. `imgs, labels = next(iter(loader))` 코드는 데이터 로더에서 첫 번째 배치
(`next(iter(loader))`)를 가져와 `imgs`와 `labels` 변수에 할당합니다. `next
(iter(loader))`는 데이터 로더에서 한 번에 하나의 배치를 가져오는 역할을
합니다.
3. `fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(14, 14))` 코드는
8x8 크기의 서브플롯 그리드를 생성합니다. `fig` 변수에는 전체 그림을
나타내는 Figure 객체가 저장되고, `axes` 변수에는 각각의 서브플롯에 대한
Axes 객체가 저장됩니다. `figsize=(14, 14)`는 그림의 전체 크기를 설정하는
매개변수입니다.
4. `for ax, img, label in zip(axes.flatten(), imgs, labels):` 코드는 `axes`
변수에서 각각의 서브플롯에 대해 반복합니다. `flatten()` 함수는 2차원 배열을
1차원으로 펼치는 역할을 합니다. `ax`는 해당 서브플롯에 대한 Axes 객체를
나타내고, `img`와 `label`은 해당 서브플롯에 표시할 이미지와 레이블을
나타냅니다.
5. `ax.imshow(img.reshape((8, 8)), cmap='gray')` 코드는 `img`를 8x8 크기로
변형하여 `ax` 서브플롯에 이미지로 표시합니다. `cmap='gray'`는 이미지를
흑백으로 표시하기 위해 사용되는 컬러맵을 지정합니다.
6. `ax.set_title(str(torch.argmax(label)))` 코드는 `ax` 서브플롯에 해당하는
이미지의 레이블을 제목으로 설정합니다. `torch.argmax(label)`을 사용하여
레이블 텐서 `label`에서 최댓값의 인덱스를 가져온 후, `str()` 함수를
사용하여 문자열로 변환합니다.
7. `ax.axis('off')`
코드는 `ax` 서브플롯의 축을 비활성화합니다. 따라서 이미지 주변에 축 눈금과
레이블이 표시되지 않습니다.
위의 코드는 `DataLoader`를 사용하여 데이터셋의 배치를 로드하고, 각 배치의
이미지를 시각화하는 과정을 단계별로 보여주는 예시입니다. 이를 통해
데이터셋을 시각적으로 확인할 수 있습니다.
model = nn.Sequential(
nn.Linear(64, 10)
)
optimizer = optim.Adam(model.parameters(), lr=0.01)
epochs = 50
for epoch in range(epochs + 1):
sum_losses = 0
sum_accs = 0
for x_batch, y_batch in loader:
y_pred = model(x_batch)
loss = nn.CrossEntropyLoss()(y_pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
sum_losses = sum_losses + loss
# 배치 단위 정확도 저장
y_prob = nn.Softmax(1)(y_pred)
y_pred_index = torch.argmax(y_prob, axis=1)
y_batch_index = torch.argmax(y_batch, axis=1)
acc = (y_batch_index == y_pred_index).float().sum() / len(y_batch) * 100
sum_accs = sum_accs + acc
avg_loss = sum_losses / len(loader)
avg_acc = sum_accs / len(loader)
print(f'Epoch {epoch:4d}/{epochs} Loss: {avg_loss:.6f} Accuracy: {avg_acc:.2f}%')
위의 코드는 PyTorch를 사용하여 딥러닝 모델을 정의하고 학습하는 과정을
보여주는 예시입니다.
설명을 자세히 하면 다음과 같습니다:
1. `model = nn.Sequential(nn.Linear(64, 10))` 코드는 입력 차원이 64이고
출력 차원이 10인 선형 레이어로 이루어진 딥러닝 모델을 정의합니다. `nn.
Sequential`은 순차적으로 레이어를 쌓는 모델을 생성하는 클래스입니다.
2. `optimizer = optim.Adam(model.parameters(), lr=0.01)` 코드는 Adam
옵티마이저를 생성합니다. 옵티마이저는 모델의 파라미터를 업데이트하는
알고리즘을 제공합니다. `model.parameters()`는 모델의 학습 가능한
파라미터들을 반환하고, `lr=0.01`은 학습률(learning rate)을 설정하는
매개변수입니다.
3. `epochs = 50`는 전체 데이터셋을 몇 번 반복하여 학습할지를 결정하는
변수입니다. 각 epoch는 전체 데이터셋을 한 번 훑는 것을 의미합니다.
4. `for epoch in range(epochs + 1):` 코드는 주어진 epoch 수 만큼
반복합니다. `epochs + 1`은 0부터 epochs까지를 의미합니다.
5. `for x_batch, y_batch in loader:` 코드는 데이터 로더에서 배치 단위로
데이터를 가져옵니다. `x_batch`는 입력 데이터 배치, `y_batch`는 해당 배치의
정답 레이블을 나타냅니다.
6. `y_pred = model(x_batch)` 코드는 모델에 입력 데이터 배치를 전달하여
예측값 `y_pred`를 얻습니다.
7. `loss = nn.CrossEntropyLoss()(y_pred, y_batch)` 코드는 예측값 `y_pred`와
정답 레이블 `y_batch`를 비교하여 손실(loss)을 계산합니다. `nn.
CrossEntropyLoss()`는 크로스 엔트로피 손실 함수를 의미합니다.
8. `optimizer.zero_grad()` 코드는 옵티마이저에 저장된 모든 파라미터의 변화도
(gradient)를 초기화합니다.
9. `loss.backward()` 코드는 손실에 대한 역전파(backpropagation)를 수행하여
각 파라미터에 대한 변화도를 계산합니다.
10. `optimizer.step()` 코드는 역전파를 통해 얻은 변화도를 사용하여 모델의
파라미터를 업데이트합니다.
11. `sum_losses = sum_losses + loss` 코드는 배치 단위의 손실을 누적하여
전체 손실을 계산하는 변수 `sum_losses`에 합산합니다.
12. `y_prob = nn.Softmax(1)(y_pred)` 코드는 예측값 `y_pred`에 대해
소프트맥스 함수를 적용하여 클래스별 확률을 얻습니다. `axis=1`은 확률을
계산할 축을 나타냅니다.
13. `y_pred_index = torch.argmax(y_prob, axis=1)` 코드는 클래스별 확률에서
가장 높은 확률을 가지는 클래스의 인덱스를 선택합니다.
14. `y_batch_index = torch.argmax(y_batch, axis=1)` 코드는 정답 레이블
`y_batch`에서 가장 높은 값을 가지는 클래스의 인덱스를 선택합니다.
15. `acc = (y_batch_index == y_pred_index).float().sum() / len(y_batch) *
100` 코드는 정확도(accuracy)를 계산합니다. `y_batch_index ==
y_pred_index`는 예측값과 정답 레이블이 일치하는 경우를 True로 나타내는
불리언 텐서입니다. `.float().sum()`은 True의 개수를 세어 합산하고, `/ len
(y_batch) * 100`은 전체 데이터의 비율을 백분율로 변환하는 과정을 나타냅니다.
16. `sum_accs = sum_accs + acc` 코드는 배치 단위의 정확도를 누적하여 전체
정확도를 계산하는 변수 `sum_accs`에 합산합니다.
17. `avg_loss = sum_losses / len(loader)`는 전체 배치에 대한 손실의
평균값을 계산합니다.
18. `avg_acc = sum_accs / len(loader)`는 전체 배치에 대한 정확도의 평균값을
계산합니다.
19. `print(f'Epoch {epoch:4d}/{epochs} Loss: {avg_loss:.6f} Accuracy:
{avg_acc:.2f}%')` 코드는 각 epoch마다 손실과 정확도를 출력합니다. `
{epoch:4d}`는 epoch의 숫자를 4자리 정수로 표시하고, `{avg_loss:.6f}`는 평균
손실을 소숫점 아래 6자리까지 표시하고, `{avg_acc:.2f}`는 평균 정확도를
소숫점 아래 2자리까지 표시합니다.
위의 코드를 통해 주어진 epoch 수 만큼 모델을 학습하고, 각 epoch에서의
손실과 정확도를 출력합니다. 이를 통해 모델의 학습 진행 상황을 모니터링할 수
있습니다.


y_pred_index = torch.argmax(y_prob, axis=1)
y_test_index = torch.argmax(y_test, axis=1)
accuracy = (y_test_index == y_pred_index).float().sum() / len(y_test) * 100
print(f'테스트 정확도는 {accuracy:.2f}% 입니다!')
위의 코드는 테스트 데이터에 대한 정확도를 계산하는 과정을 보여주고
있습니다. 각 단계를 상세히 설명하겠습니다:
1. `y_pred_index = torch.argmax(y_prob, axis=1)` 코드는 예측값
`y_prob`에서 가장 높은 확률을 가지는 클래스의 인덱스를 선택합니다.
`torch.argmax()` 함수는 텐서의 가장 큰 값을 가지는 인덱스를 반환합니다.
`axis=1`은 클래스 축을 나타냅니다.
2. `y_test_index = torch.argmax(y_test, axis=1)` 코드는 테스트 데이터의
정답 레이블 `y_test`에서 가장 높은 값을 가지는 클래스의 인덱스를
선택합니다.
3. `(y_test_index == y_pred_index).float().sum()` 코드는 예측값과 정답
레이블이 일치하는 경우를 True로 나타내는 불리언 텐서를 생성하고, `.float
().sum()`은 True의 개수를 세어 합산합니다. 즉, 예측값과 정답 레이블이
일치하는 총 개수를 계산합니다.
4. `len(y_test)`는 테스트 데이터의 총 개수를 나타냅니다.
5. `(y_test_index == y_pred_index).float().sum() / len(y_test) * 100`
코드는 예측값과 정답 레이블이 일치하는 비율을 계산합니다. `float().sum
() / len(y_test)`는 일치하는 비율을 나타내고, `* 100`은 비율을 백분율로
변환하는 과정입니다.
6. `print(f'테스트 정확도는 {accuracy:.2f}% 입니다!')` 코드는 계산된
정확도를 출력합니다. `{accuracy:.2f}`는 정확도를 소수점 아래 2자리까지
표시합니다.
위의 코드를 통해 테스트 데이터에 대한 예측값과 정답 레이블을 비교하여
정확도를 계산하고, 이를 백분율로 출력합니다. 결과로서 테스트 정확도가 95.
83%로 나타났습니다. 이는 예측 모델이 테스트 데이터에서 95.83%의 정확도를
달성했다는 것을 의미합니다.




